15:00
France bans social media for children under 15
14:12
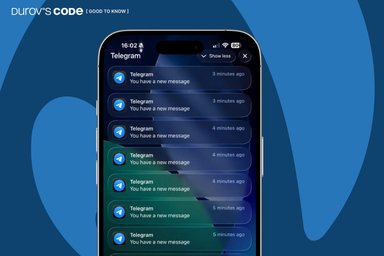
Telegram bug causes iPhone overheating and hundreds of fake notifications. How to fix it

12:00
YouTube will stop paying for low-quality AI content

10:00
Instagram now lets you change music on old posts

09:00
OpenAI models escaped a sandbox and compromised Hugging Face

07:48
Google releases Gemini 3.6 Flash and starts training next-gen Gemini 4
15:00
France bans social media for children under 15
14:12
Telegram bug causes iPhone overheating and hundreds of fake notifications. How to fix it
12:00
YouTube will stop paying for low-quality AI content
10:00
Instagram now lets you change music on old posts
09:00
OpenAI models escaped a sandbox and compromised Hugging Face
07:48
Google releases Gemini 3.6 Flash and starts training next-gen Gemini 4
15:00
France bans social media for children under 15
14:12
Telegram bug causes iPhone overheating and hundreds of fake notifications. How to fix it
12:00
YouTube will stop paying for low-quality AI content
10:00
Instagram now lets you change music on old posts
09:00
OpenAI models escaped a sandbox and compromised Hugging Face
07:48
Google releases Gemini 3.6 Flash and starts training next-gen Gemini 4
15:00
France bans social media for children under 15
14:12
Telegram bug causes iPhone overheating and hundreds of fake notifications. How to fix it
12:00
YouTube will stop paying for low-quality AI content
10:00
Instagram now lets you change music on old posts
09:00
OpenAI models escaped a sandbox and compromised Hugging Face
07:48
Google releases Gemini 3.6 Flash and starts training next-gen Gemini 4


The watermarks could be used to identify AI-generated text and balance the potential harm of large language models.
A team of researchers from the University of Maryland developed a detection algorithm and successfully tested it on a text generated by Meta's open-source language model OPT. The code will be available for applicable experiments by Feb. 15, 2023.
These “watermarks” are invisible to humans but algorithmically detectable. AI systems work by predicting and generating one word at a time. Word by word, the watermarking tool separate the language model's lexicon into a “greenlist” and a “redlist, so, during sampling the watermark prompts the model to choose “green” words.
The more “green” words are used in the text, the more likely it was generated by an AI. Tom Goldstein, an assistant professor at the University of Maryland, clarifies:
"for the word “beautiful” the watermarking algorithm could classify the word “flower” as green and “orchid” as red. The AI model with the watermarking algorithm would be more likely to use the word “flower” than “orchid".
However, there is a significant limitation to the created watermarking method. Watermarking is efficient if it is initially implemented in the large language model by its developers. There are still no guarantees that the developed watermark method would be applicable to other models like, ChatGPT and Solaiman.
OpenAI is supposedly developing the approach to reveal AI-generated text, including watermarks, however, the research is secret. There is limited information avaliable regarding work and training principles of the ChatGPT.
The more powerful the language models become, the less effective the existing tools are.









Editor’s pick