12:00
Major publishers consider blocking Googlebot as AI search slashes traffic

08:30
Apple plans to refresh its entire Mac lineup with around 11 new models

21:00
Samsung reveals smart glasses powered by Gemini

15:00
France bans social media for children under 15
14:12
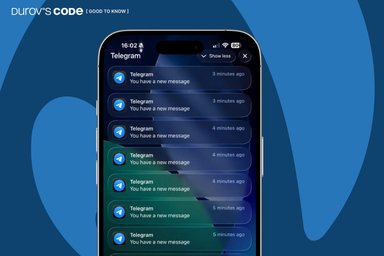
Telegram bug causes iPhone overheating and hundreds of fake notifications. How to fix it

12:00
YouTube will stop paying for low-quality AI content
12:00
Major publishers consider blocking Googlebot as AI search slashes traffic
08:30
Apple plans to refresh its entire Mac lineup with around 11 new models
21:00
Samsung reveals smart glasses powered by Gemini
15:00
France bans social media for children under 15
14:12
Telegram bug causes iPhone overheating and hundreds of fake notifications. How to fix it
12:00
YouTube will stop paying for low-quality AI content
12:00
Major publishers consider blocking Googlebot as AI search slashes traffic
08:30
Apple plans to refresh its entire Mac lineup with around 11 new models
21:00
Samsung reveals smart glasses powered by Gemini
15:00
France bans social media for children under 15
14:12
Telegram bug causes iPhone overheating and hundreds of fake notifications. How to fix it
12:00
YouTube will stop paying for low-quality AI content
12:00
Major publishers consider blocking Googlebot as AI search slashes traffic
08:30
Apple plans to refresh its entire Mac lineup with around 11 new models
21:00
Samsung reveals smart glasses powered by Gemini
15:00
France bans social media for children under 15
14:12
Telegram bug causes iPhone overheating and hundreds of fake notifications. How to fix it
12:00
YouTube will stop paying for low-quality AI content


The tech giant is facing a wide-ranging lawsuit accusing it of unlawfully scraping data from millions of users without their consent to train its AI tools.
The proposed class action suit, filed by Clarkson Law Firm in a federal court in California, targets Google, its parent company Alphabet, and its AI subsidiary DeepMind.
The complaint alleges that Google engages in hidden data theft by stealing and using vast amounts of user-generated content from hundreds of millions of Americans. This data is allegedly used to train Google's artificial intelligence, including the popular Bard chatbot. The lawsuit also alleges that Google used copyrighted works and the entire digital footprint of users to enhance the capabilities of its artificial intelligence.
Representatives from Google, Alphabet and DeepMind have not yet responded to the lawsuit. The lawsuit follows Google's recent revision of its privacy policy, which directly states that publicly available information can be used to train artificial intelligence models and tools such as Bard. Google explained that this change only makes existing practices more transparent.
The lawsuit comes amid growing attention to the use of copyrighted material and personal data in artificial intelligence training. Concerns have been raised about the inclusion of protected works in training datasets and the potential use of personal data, including data from children.
Tim Giordano, one of the attorneys at Clarkson bringing the suit against Google, emphasized:
Google needs to understand that ‘publicly available’ has never meant free to use for any purpose.
The lawsuit seeks an injunction temporarily halting commercial access to and development of Google's generative AI tools, as well as damages for individuals whose data was allegedly misused. The company named eight plaintiffs, including a minor.









Editor’s pick