08:30
Pavel Durov questioned again in Paris for over six hours

08:00
OpenAI launches GPT-Live, a new generation of voice models for ChatGPT

22:00
China warns of alleged backdoor in Anthropic’s Claude Code

14:13
GPT-5.6 set for public release after US lifts restrictions

13:00
US companies are turning to cheaper Chinese AI models as costs rise
10:00
Claude Cowork is coming to mobile and the web with background tasks
08:30
Pavel Durov questioned again in Paris for over six hours
08:00
OpenAI launches GPT-Live, a new generation of voice models for ChatGPT
22:00
China warns of alleged backdoor in Anthropic’s Claude Code
14:13
GPT-5.6 set for public release after US lifts restrictions
13:00
US companies are turning to cheaper Chinese AI models as costs rise
10:00
Claude Cowork is coming to mobile and the web with background tasks
08:30
Pavel Durov questioned again in Paris for over six hours
08:00
OpenAI launches GPT-Live, a new generation of voice models for ChatGPT
22:00
China warns of alleged backdoor in Anthropic’s Claude Code
14:13
GPT-5.6 set for public release after US lifts restrictions
13:00
US companies are turning to cheaper Chinese AI models as costs rise
10:00
Claude Cowork is coming to mobile and the web with background tasks
08:30
Pavel Durov questioned again in Paris for over six hours
08:00
OpenAI launches GPT-Live, a new generation of voice models for ChatGPT
22:00
China warns of alleged backdoor in Anthropic’s Claude Code
14:13
GPT-5.6 set for public release after US lifts restrictions
13:00
US companies are turning to cheaper Chinese AI models as costs rise
10:00
Claude Cowork is coming to mobile and the web with background tasks



Recently, someone at Google accidentally published internal documents on GitHub.
SEO specialist Rand Fishkin said that the source shared a large amount of Google's internal documents with him and he examined them. The documentation in question is called Google API Content Warehouse.
About 2,500 pages of internal documentation describe the work of Google's search algorithm. At the moment, the company has not decided to comment on the authenticity of the leak.
- According to Fishkin, the documents describe Google's search API and describe what information is available to employees.
- The details described in the documents have a lot of technical information that is mostly only understandable to SEO specialists.
- The contents of the leaked documents are also not necessarily proof that Google uses specific search ranking techniques.
The leak basically describes what data Google collects from web pages, sites and search engines, explains SEO expert Mike King. Inside is a description of the factors and components that affect search engine results.
Both experts assure that some of the data in the documents contradict Google's public statements:
Lied’ is harsh, but it’s the only accurate word to use here,
King writes.
While I don’t necessarily fault Google’s public representatives for protecting their proprietary information, I do take issue with their efforts to actively discredit people in the marketing, tech, and journalism worlds who have presented reproducible discoveries.
Fishkin said the company is not disputing the veracity of the leak, but an employee asked him to change some of the phrasing in the leaked publication regarding how an event was described.
One example of a “lie” concerns the use of Chrome browser data in ranking: Google officially denies this, but the leaked documents say otherwise:
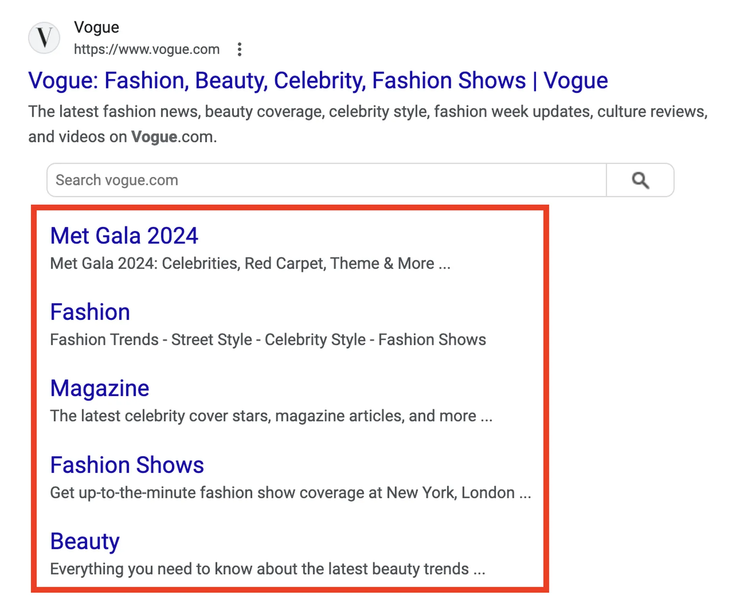
According to the documents, the highlighted links to sections of the website in the screenshot may be partly suggested by Google based on user activity data in Chrome.








Editor’s pick