11:00
Google introduces video selfie verification for account recovery

09:00
More details emerge on Apple's upcoming device subscription program

12:00
Major publishers consider blocking Googlebot as AI search slashes traffic

08:30
Apple plans to refresh its entire Mac lineup with around 11 new models

21:00
Samsung reveals smart glasses powered by Gemini

15:00
France bans social media for children under 15
11:00
Google introduces video selfie verification for account recovery
09:00
More details emerge on Apple's upcoming device subscription program
12:00
Major publishers consider blocking Googlebot as AI search slashes traffic
08:30
Apple plans to refresh its entire Mac lineup with around 11 new models
21:00
Samsung reveals smart glasses powered by Gemini
15:00
France bans social media for children under 15
11:00
Google introduces video selfie verification for account recovery
09:00
More details emerge on Apple's upcoming device subscription program
12:00
Major publishers consider blocking Googlebot as AI search slashes traffic
08:30
Apple plans to refresh its entire Mac lineup with around 11 new models
21:00
Samsung reveals smart glasses powered by Gemini
15:00
France bans social media for children under 15
11:00
Google introduces video selfie verification for account recovery
09:00
More details emerge on Apple's upcoming device subscription program
12:00
Major publishers consider blocking Googlebot as AI search slashes traffic
08:30
Apple plans to refresh its entire Mac lineup with around 11 new models
21:00
Samsung reveals smart glasses powered by Gemini
15:00
France bans social media for children under 15


The system enables users to generate 3D models from text prompts in 1-2 mins.
The process consists of two stages: text-to-image and image-to-3D modeling. Point-E generates from text a low-resolution point cloud – a set of points in space.
A team of researchers at San Francisco-based OpenAI describe the process:
"Our method first generates a single synthetic view using a text-to-image diffusion model, and then produces a 3D point cloud using a second diffusion model which conditions on the generated image."
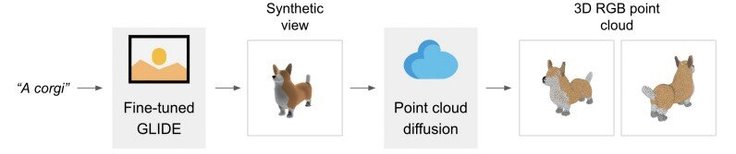
The 3D point cloud generated by Point-E differs from an image in traditional sense. But point cloud form let the modeling process be quick and easy.
The developers explain:
"While our method still falls short of the state-of-the-art in terms of sample quality, it is one to two orders of magnitude faster to sample from, offering a practical trade-off for some use cases."
The process takes one to two minutes and requires no special skills. The 3D point cloud model generated by Point-E could be considered as an intermediate model in, for example, gaming, animation or 3D printing.
The team conclude:
"We refer to our system as Point·E, since it generates point clouds efficiently."
The system has open access; you may find it on GitHub.
Earlier in December launched Open AI a chatbot ChatGPT powered with a large language model that uses deep learning to produce human-like text. ChatGPT generates essays and solve math tasks.









Editor’s pick