13:35
EU fines AliExpress €550 million over illegal and unsafe products

12:00
RedMagic Astra 2 matches ROG Xbox Ally X gaming performance

10:38
Thousands of AI-generated fake books appear on Apple Books and Amazon

08:00
Hugging Face reveals cyberattack carried out by autonomous AI agents

09:00
Apple abandons high-end Mac Pro chips, plans refresh of entire iPad lineup

08:45
Apple is using AI to record customer conversations in some Apple Stores
13:35
EU fines AliExpress €550 million over illegal and unsafe products
12:00
RedMagic Astra 2 matches ROG Xbox Ally X gaming performance
10:38
Thousands of AI-generated fake books appear on Apple Books and Amazon
08:00
Hugging Face reveals cyberattack carried out by autonomous AI agents
09:00
Apple abandons high-end Mac Pro chips, plans refresh of entire iPad lineup
08:45
Apple is using AI to record customer conversations in some Apple Stores
13:35
EU fines AliExpress €550 million over illegal and unsafe products
12:00
RedMagic Astra 2 matches ROG Xbox Ally X gaming performance
10:38
Thousands of AI-generated fake books appear on Apple Books and Amazon
08:00
Hugging Face reveals cyberattack carried out by autonomous AI agents
09:00
Apple abandons high-end Mac Pro chips, plans refresh of entire iPad lineup
08:45
Apple is using AI to record customer conversations in some Apple Stores
13:35
EU fines AliExpress €550 million over illegal and unsafe products
12:00
RedMagic Astra 2 matches ROG Xbox Ally X gaming performance
10:38
Thousands of AI-generated fake books appear on Apple Books and Amazon
08:00
Hugging Face reveals cyberattack carried out by autonomous AI agents
09:00
Apple abandons high-end Mac Pro chips, plans refresh of entire iPad lineup
08:45
Apple is using AI to record customer conversations in some Apple Stores


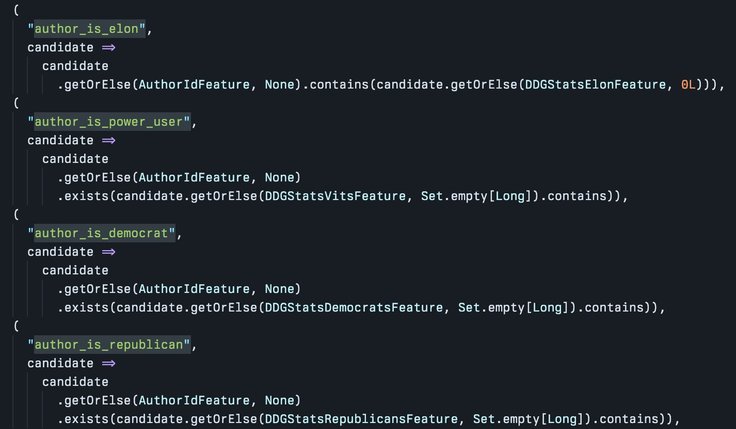
Users already found a parameter "is_author_elon".
Late Friday night Elon Musk published Twitter's Recommendation Algorithm on GitHub. The company will be updating its recommendation algorithm based on user suggestions every 24 to 48 hours, he claimed.
Enthusiasts developers have already found parameter "is_author_elon" besides the democrat, republican and “Power User” labels. During the Spaces session afternoon, a Twitter engineer said that the labels were used only for metrics. But Musk anyway said, that Twitter would delete them.
Researchers are already started to explore what was behind the feed all this time. As they figured out, Twitter trying to 'predict' the future virality of the tweet and how likely you are to interact with another user.
The company excluded everything that could harm users' data or the ability to defend the platform from bad actors. For example, you can't find Twitter's ad recommendations or the data used to train Twitter's recommendation algorithm.
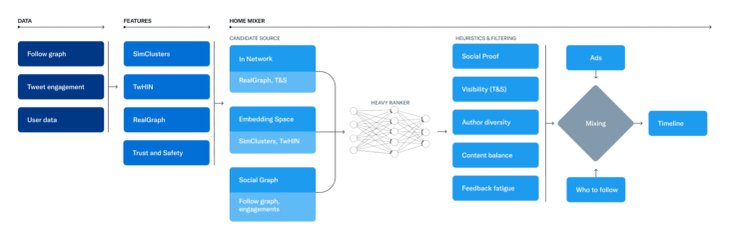
Anyway, researchers started to do their work. As they figured out, Twitter's algorithm is fairly complex and made up of multiple models, including the model "not safe for work". It determines the likelihood of a Twitter user interacting with another user and also a Twitter user's "reputation".
Then several neural networks are responsible for ranking the tweets and recommending accounts to follow. There's also a filtering component that hides tweets to "support legal compliance, improve product quality, increase user trust, protect revenue through the use of hard-filtering, visible product treatments, and coarse-grained downranking".
The company also revealed an engineering blog post with more details on the recommendation pipeline. It claims, that Twitter runs algorithms approximately five billion times per day.
“We attempt to extract the best 1,500 tweets from a pool of hundreds of millions … Today, the For You timeline consists of 50% [tweets from people you don’t follow] and 50% [tweets from people you follow] on average, though this may vary from user to user"
For ranking tweets, the company used a ~48-million-parameter neural network that is continuously trained on tweet interactions to optimize for 'positive engagement'. Twitter users don't see all the 1,500 tweets. They're filtered according to content restrictions, other criteria, and factors considered by the models.










Editor’s pick